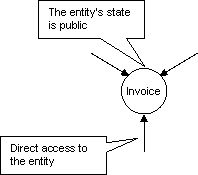
I en klassisk arkitektur skyddas informationen enbart av en databas under korta transaktioner (ACID). Men under en längre tid, som t ex en faktura lever innan den betalats, kan data vara åtkomligt för vilken process som helst och ligger helt oskyddad för förändringar. Samma sak gäller diverse objekt-ramverk (ex. Spring el. EJB). Där görs fakturaobjektet åtkomligt för vilken process som helst under en fakturas livstid. Man kan ändra tillståndet i vilken ordning man vill och från vilken process som helst.
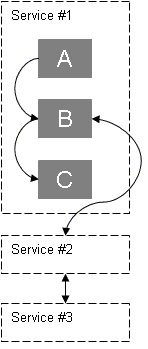
I ett processorienterat perspektiv skyddas fakturan (entiteten) under processens livstid. All access till fakturan går via klara definierade regler för vem och när de kan få tillgång till fakturainformationen och förändra dess tillstånd.

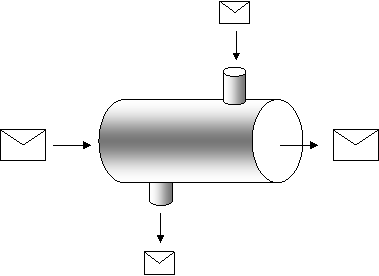
Man kan se processen som en pipeline där bilderna ovan är tvärsnittet av den skyddande processen. En pipeline har definierade access-punkter (end points) som rent semantiskt beskrivs i en processdefinition eller ett processpråk (BPEL4WS).